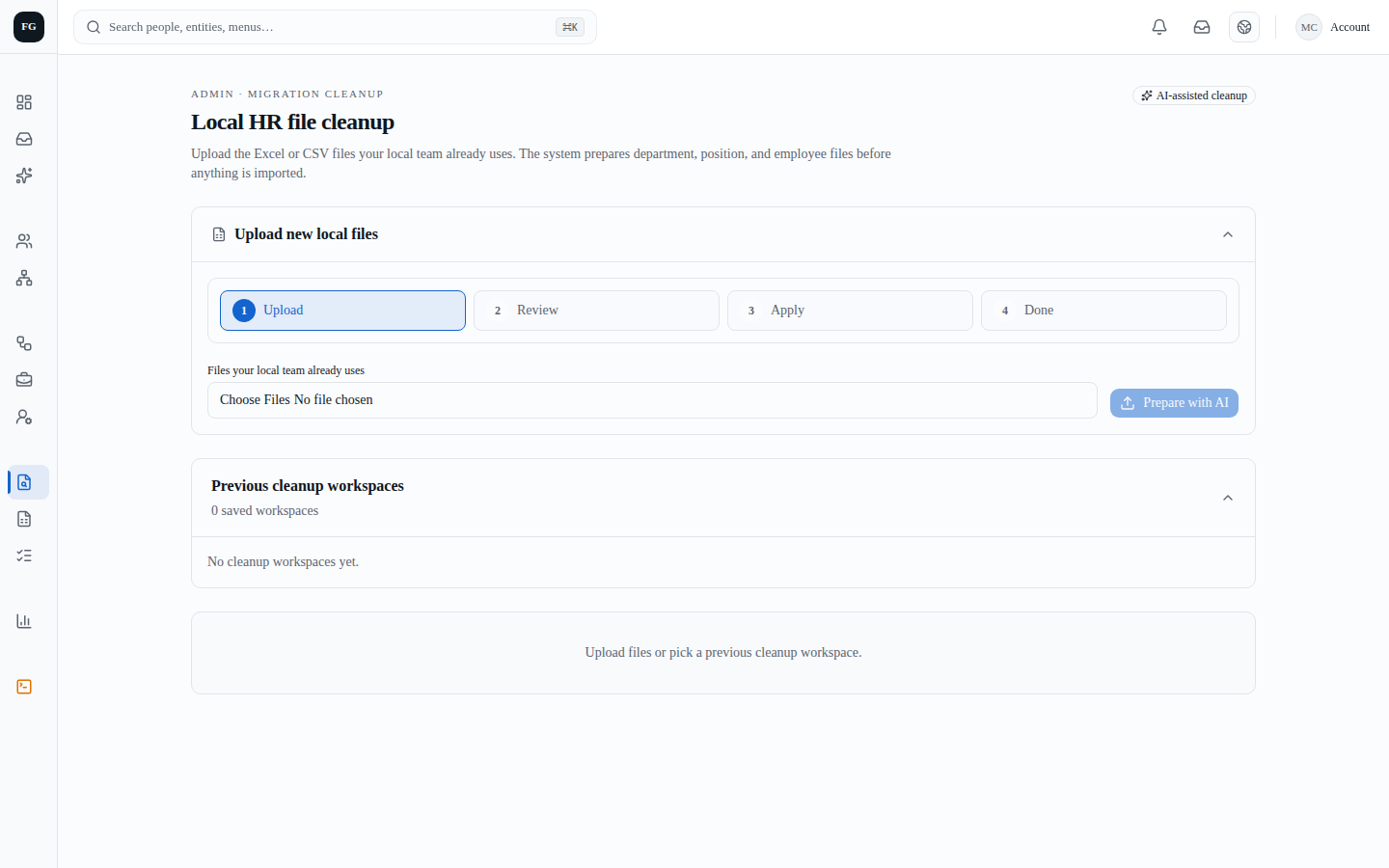
업로드와 검수 화면
Data Intake, Data Roundtrip, People, Organization, Quality, Audit 화면이 있다.
실제 프로젝트 사례 03
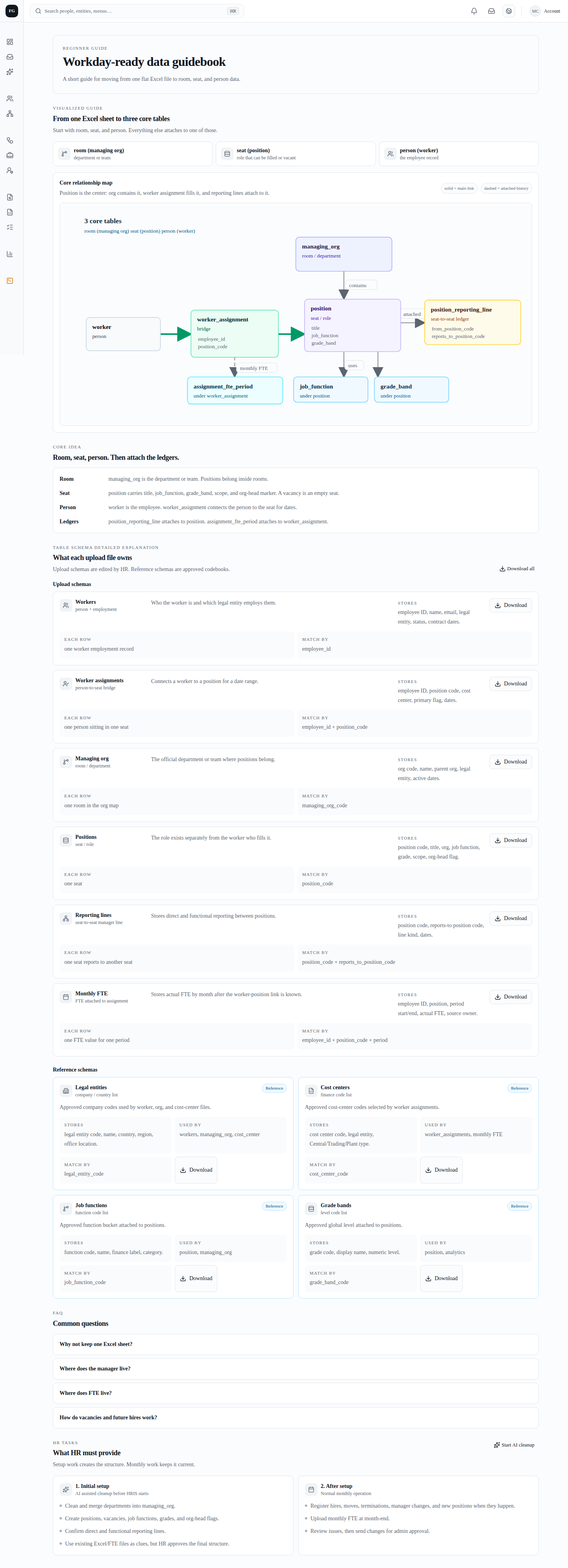
HRIS는 사람이 들어 있는 엑셀 한 장을 그대로 믿지 않는다. 조직은 방, 포지션은 의자, 직원은 사람으로 나누고, AI는 원장을 직접 고치지 않고 “이렇게 정리하면 좋겠다”는 초안을 만든다.
실제 화면 자료
HRIS는 초보자도 DB 구조를 이해하도록 안내 화면을 두고, 로컬 HR 파일은 별도 Data Intake 흐름으로 받는다.
한 줄 지도
난잡한 HR 파일을 DB에 바로 넣지 않고, 구조를 분석하고, 누락 질문을 만들고, 사람이 승인할 초안으로 바꾼다.
Data Intake, Data Roundtrip, People, Organization, Quality, Audit 화면이 있다.
Next route와 server action이 업로드, 검증, 승인 요청, 롤백을 처리한다.
person, employment, assignment, managing_org, position, assignment_fte_period가 중심이다.
Pipeline
핵심은 AI가 원장을 직접 바꾸지 않는다는 점이다. AI는 서류를 분류하는 접수 담당자이고, 최종 반영은 승인자가 한다.
로컬 HR이 쓰던 employee, org, payroll, FTE 파일을 올린다.
파일별 sheet, column, sample row, 누락값을 먼저 기계적으로 읽는다.
Codex CLI가 live DB schema와 파일 profile을 읽고 mapping plan을 만든다.
부서, 포지션, 직원 초안을 사람이 보고 고친다. 원장 반영 전 단계다.
HR_ADMIN 승인 뒤에만 적용되고, audit log와 rollback 근거가 남는다.
AI 기본 개념 연결
스키마는 장부의 칸 설계다. 어떤 칸에 어떤 값이 들어갈지 미리 정한다.
사용자 권한, 법인 scope, 최신 DB schema, 파일 profile, sample rows만 넣는다.
프론트는 파일과 선택값을 API로 보내고, 백엔드는 세션과 결과를 응답한다.
AI는 원장을 직접 수정하지 않는다. 초안을 만들고 사람이 승인한다.
감사 로그는 CCTV와 같다. 업로드, AI 분석, 승인, 롤백을 추적한다.
성공한 LLM 호출은 model, token, estimated_cost_usd와 함께 `llm_usage_log`에 남긴다.
Prompt Example
이 프롬프트의 핵심은 “고쳐라”가 아니라 “검수 계획을 만들어라”다. AI에게 펜을 주지 않고 포스트잇만 주는 구조다.
역할: HR 데이터 마이그레이션 분석가
절대 규칙:
- master data를 직접 import하거나 수정하지 않는다.
- 사용자 legal_entity_scope 밖 데이터는 제안하지 않는다.
- 민감 필드는 표시하고, 사람이 확인할 질문을 만든다.
- 결과는 structured JSON으로만 반환한다.
입력:
- live DB schema catalog
- HRIS business target catalog
- workbook profile
- sample rows
- current user scope{
"sourceClassification": "employee_master + org + fte",
"mappingSuggestions": [
{
"sourceColumn": "부서명",
"targetTable": "managing_org",
"targetColumn": "name"
}
],
"missingFields": ["legal_entity_code"],
"sensitiveFields": ["work_email"],
"questionsForLocalHr": [
"부서 코드가 전역 기준과 같은가요?"
],
"hrisUploadDraft": "review_required"
}Call → Result
실제 파일 내용은 공개하지 않고, 어떤 모양의 요청과 응답이 오가는지만 보여준다.
{
"route": "/api/admin/data-intake",
"files": [
"employees.xlsx",
"org_units.xlsx",
"monthly_fte.xlsx"
],
"mode": "prepare_with_ai",
"legal_entity_scope": ["KR01"]
}{
"session_id": "intake_2026_06_25_01",
"status": "review_required",
"file_count": 3,
"drafts": {
"org_units_to_create": 8,
"positions_to_create": 42,
"employee_rows": 3544
},
"logs": {
"llm_usage_log_id": "usage_881",
"audit_log_id": "audit_441"
}
}Context Stack
로그인 사용자의 역할과 접근 가능한 법인을 먼저 넣는다. AI가 범위를 넘지 못하게 한다.
현재 DB의 table, column, FK, enum을 넣는다. 오래된 문서가 아니라 실제 장부 구조를 기준으로 삼는다.
파일명, sheet명, column명, sample rows, 누락 패턴을 넣는다.
room, seat, person 규칙과 “AI는 원장을 직접 고치지 않는다”는 금지선을 넣는다.
mapping plan, 질문, 민감 필드, HRIS 업로드 초안만 결과로 받는다.
DB View
| 테이블 | 역할 | 초보자 비유 |
|---|---|---|
| managing_org | 부서와 팀 구조 | 방 |
| position | 조직 안의 역할 자리 | 의자 |
| person | 실제 사람의 신원 카드 | 사람 |
| assignment | 사람이 어느 의자에 앉았는지 | 좌석 배치표 |
| assignment_fte_period | 월별 실제 FTE | 월별 근무 비율 기록 |
| audit_log | 변경과 승인 기록 | CCTV 기록 |
강의 포인트
사람, 자리, 월별 FTE가 한 줄에 섞이면 중복과 오류가 늘어난다. DB는 장부를 나눠서 연결한다.
AI가 바로 원장을 고치면 위험하다. 대신 서류를 분류하고 질문을 만들고 초안 봉투를 만든다.
HR 데이터는 민감하다. 누가 요청했고 누가 승인했는지 남겨야 나중에 되돌릴 수 있다.